Your Certification Body Isn't Running Exams Anymore. It's Running Trust Infrastructure.
Most professional credentialing organizations still describe themselves as exam bodies. The hospitals, regulators, employers, and licensing boards that depend on them know differently. Here is the structural gap that creates — and what closing it looks like.

The exam ended the moment the candidate submitted their answers. What your organization is actually operating every hour of every day is something far more consequential.
The question nobody asks at board meetings
Technology budgets at professional credentialing organizations have grown every year for the past decade. New exam delivery platforms. Upgraded candidate portals. Digital badging. Cloud migrations. Proctoring technology.
Every investment made sense in isolation.
And yet the organizations that depend on credentialing data tell the same story year after year. Verification requests that take days to answer. Certification lapses that travel slowly through systems. Eligibility checks that run against data that is hours or days old.
The same question that sits unasked in every board review applies here with far higher stakes.
If these organizations have invested this heavily in technology, why is the data still slow?
The answer is structural. And it starts with a misidentification that most credentialing organizations make about what their core product actually is.
The exam is not the product
Ask any professional credentialing organization what it does and the answer comes back in some version of the same sentence.
We develop and administer examinations. We award certifications. We credential professionals in our field.
That description was accurate when it was written. It no longer captures what the organization actually operates.
No external stakeholder ever interacts with an exam.
A hospital credentialing committee does not interact with an exam. A malpractice insurer does not interact with an exam. A state licensing board does not interact with an exam. A law firm verifying a new hire does not interact with an exam.
They interact with a decision.
Is this professional certified and in good standing right now? Has this certification lapsed? Has this individual had a disciplinary action? Can that status be confirmed instantly and on record?
These are not data questions. They are decision questions. And the answers carry immediate clinical, legal, financial, and institutional consequence.
The exam was one input into the system. The real product is a trustworthy, consistent, and verifiable decision made at the moment it is needed by a system designed to make it.
Most organizations have not yet built their infrastructure to produce that product reliably.
Why credentialing infrastructure becomes fragmented?
Every organization in this space built the same architecture. Not deliberately. In layers, over years, as each new requirement arrived.
It starts with the exam delivery system. Purpose built to record one thing. Pass or fail on a specific date. The data model reflects that purpose. A transaction record. Not a living professional record.
Then the candidate registry. A separate system to track who candidates are across their engagement with the organization. Built separately because it needs different access controls, different ownership, and a different update cadence than the scoring system.
Then the certification status system. Because a pass result is the beginning of a credential lifecycle, not the end. Renewals, reinstatements, voluntary surrenders, status changes across multi year periods. Another system. Another data model. Another team.
Then the continuing education and MOC tracking platform. Because maintenance of certification requirements arrived years after the original system was built and could not be accommodated within it. For most organizations this is a third party platform, integrated by scheduled data feed rather than by design.
Then the verification API. Because external stakeholders began demanding programmatic, real time access to certification data. The API was built on top of the existing systems because there was no other choice. It queries them in sequence, assembling an answer with the latency of the slowest source in the chain.
Then the disciplinary database. Managed by a different authority. Connected via data exchange agreements that predate modern data infrastructure expectations. Monthly batch files. Scheduled exports. Periodic reconciliations.
Then the reporting layer. Because leadership, accreditors, and regulators need different views of the same underlying data on different schedules in different formats.
Seven layers. Each designed for a specific purpose. None designed to work as a unified credential data platform.
The result is the same across every professional sector we work in.
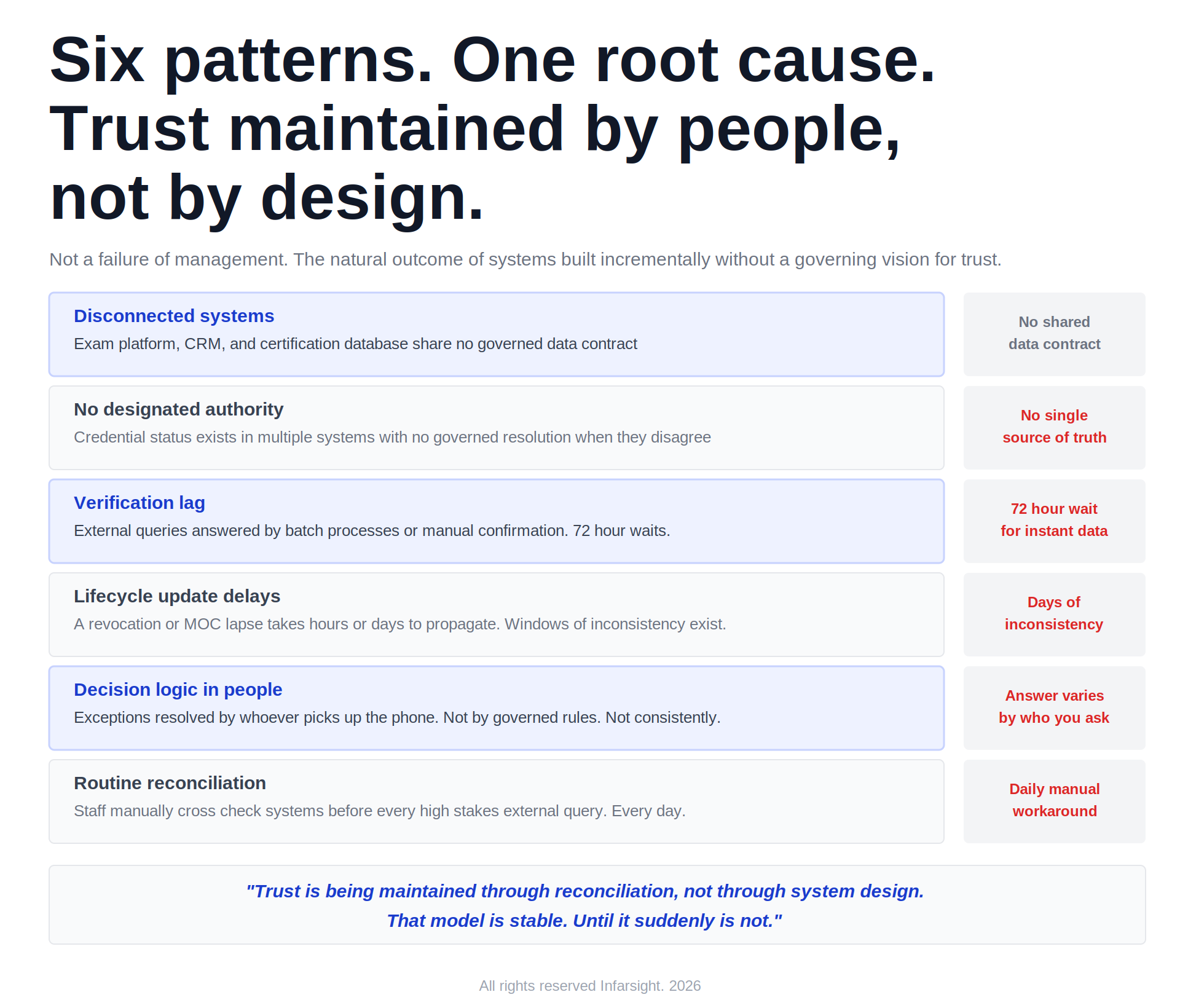
The most consequential professional decisions in an entire field assembled from systems that were never designed to share data in real time, governed by rules that live in institutional memory, and maintained through a daily practice of manual reconciliation that absorbs significant staff capacity and introduces windows of inconsistency between every update cycle.
This is the fragmented trust model. It is not a failure of management. It is the natural outcome of systems built incrementally without a governing vision for trust as a first class architectural concern.
Where trust breaks
Trust rarely fails in a dramatic, visible collapse.

It erodes through small inconsistencies. Moments where the answer a system provides does not match the authoritative reality the organization believes it is maintaining.
Here is what that looks like in practice across four sectors.
In medical credentialing, a hospital submits a verification request for a physician scheduled to begin privileges on Monday. Staff query the exam database. Pull the certification status. Check the disciplinary registry. In sequence. Manually. Across three systems. The response goes out by email. Turnaround is three business days.
The physician starts Monday. The verification arrives Thursday.
This is not a staffing problem. It is an architecture problem. The staff member handling this verification was efficient within the constraints of the architecture she was given. The three day turnaround was not slowness. It was the minimum the architecture allowed.
In nursing credentialing, a registered nurse misses a continuing education deadline. The tracking platform records the missed requirement. The certification status system does not receive an automatic update. The process requires a nightly reconciliation job to run, which feeds a file into the certification system, which feeds the licensing registry via a weekly export, which is read by third party verification services via a daily snapshot.
For six days every system a third party queries shows an active certification.
The data existed. The architecture was not designed to move it at the speed the situation required.
In legal credentialing, a candidate with a failed prior examination attempt registers for the next window. The eligibility check queries the candidate registry. The failed result lives in a different partition of the scoring system, updated by a batch process that runs at 2am. The registration is processed at 11pm. The eligibility check clears. The candidate books a seat and pays a non refundable fee.
By the time the morning batch runs and flags the ineligibility, the candidate has a confirmed appointment.
The data was there. The architecture could not surface it at the moment the decision was made.
In technology credentialing, an enterprise team is verifying the professional credentials of a contractor workforce. The workforce holds certifications from seven different bodies. Each body has its own verification system, its own update cadence, and its own response time. Some return answers in real time. Some require manual requests. Some batch responses with a 48 hour turnaround.
The compliance team builds a manual reconciliation process that takes two weeks each renewal cycle.
The credentials exist. The infrastructure to consume them at the speed enterprise compliance environments require does not.
Why this is not an operational problem
The natural response to each of these situations is to hire more staff or improve the workflow.
That response misdiagnoses the problem.
The staff member who took three days to complete the physician verification was not slow. She was doing exactly what the architecture required. The coordinator who manages CE compliance is not disorganised. She is filling a gap the systems left open. The team running the two week reconciliation cycle is not inefficient. They are doing the only job the architecture assigned to them.
These are architecture problems. And architecture problems do not respond to workflow fixes.
There is also a cost dimension that does not appear on any report.
The direct cost is visible but misattributed. Headcount grows. The assumption is volume drove it. More often the headcount is absorbing reconciliation overhead, not the work itself.
The indirect cost is invisible. Every manual step in a verification workflow is a window of inconsistency. A certification status that has changed in one system but not yet propagated to another. A disciplinary action recorded in one authority but not yet reflected in the registry a hospital will query. These windows do not appear as integration failures. They appear as individual incidents. Each one absorbed. Each one resolved quietly. The pattern never surfected as a structural issue because no single incident was large enough to demand a structural response.
The reputational cost is the hardest to measure. When external stakeholders encounter repeated friction in verification workflows, they build their own redundant checks. They stop relying on the primary source as the single authoritative answer. They begin treating the credentialing organization as one input among several rather than the definitive authority. That erosion does not happen in a moment. It accumulates over years. It becomes visible only when the organization tries to assert authority it has gradually lost.
And the AI risk is the most urgent concern right now. Across every professional sector, the pressure to deploy AI assisted credentialing workflows is accelerating. But AI does not create consistency. It scales whatever patterns already exist in the underlying data. On a fragmented architecture, AI produces faster inconsistencies, harder to trace errors, and less defensible decisions. The architectural foundation must be stable before AI is introduced. Organizations that reverse this sequence will be retrofitting governance while managing AI amplified operational failures. That is the hardest possible version of this problem.
Where most organizations are today
The credentialing organizations we work with and study sit across five recognisable stages of maturity. Not a hierarchy of success or failure. A description of where the architectural investment has and has not yet been made.
Stage 1. Exam centric. The focus is test delivery, scoring, and basic candidate management. The exam transaction is the primary data object. Everything downstream is handled manually or informally.
Stage 2. Record centric. Multiple systems store overlapping data about the same professionals. No single authoritative record. Trust maintained through periodic reconciliation. Most organizations in professional credentialing started here and many remain.
Stage 3. Authority centric. A designated system of record. Defined update protocols. Clear ownership of the credential lifecycle. The organization knows which system holds authoritative status at any given moment. But the decision logic that interprets that status may still be manual and inconsistent. Most organizations across medical, legal, financial, engineering, and technology credentialing currently sit between Stage 2 and Stage 3.

Stage 4. Decision centric. Explicit rules, consistent logic, and real time decision capability across all credential states. Every certification status can be determined programmatically, instantly, and defensibly. Verification responses are generated by the system, not assembled by staff. Lifecycle events propagate automatically. Exceptions route through governed workflows rather than ad hoc escalation. Very few organizations have fully reached Stage 4.
Stage 5. AI augmented trust. Automated monitoring of certification states. Predictive compliance alerts before deadlines are missed. Anomaly detection that surfaces inconsistencies before they reach external stakeholders. Intelligent exception routing with human oversight at critical decision points. This stage requires Stage 4 as a foundation. It cannot be built on a fragmented base.
The gap between Stage 3 and Stage 4 is where the greatest strategic leverage lies. It is also where the architectural investment delivers the highest return relative to the risk it eliminates.
The missing layer
When we look at the data architecture of most credentialing organizations, the same gap appears regardless of sector, size, or technical maturity.
Most organizations have invested heavily in two categories of capability.
Systems of record. The databases, platforms, and exam management systems that store candidate and credential data. These exist. The data is there.
Systems of engagement. The portals, interfaces, and APIs that allow professionals, staff, employers, and boards to interact with that data. These also exist, within the constraints of the data they consume.
What is almost universally absent is the layer that sits between storage and engagement.
A defined, governed, and explicitly architected decision layer.
The decision layer is what answers the questions that actually matter to everyone who depends on certification data.
How is certification status determined at any given moment and by which system? What rules govern eligibility, validity, MOC compliance, and exceptions? How are exceptions identified, routed, and resolved in the system, not by a person? What is the single source of truth when systems disagree? How quickly can a certification decision be produced and externally verified? How are decisions audited and made defensible after the fact?
Without this layer, decisions are slow because human interpretation of conflicting data introduces delay into what should be an instantaneous query. Decisions are inconsistent because the answer varies by system, by staff member, and by time of day. And decisions are difficult to audit because the logic that produced them exists in email threads and institutional memory rather than in governed rules.
The core structural problem is this.
Trust is being maintained through reconciliation, not through system design.
This model appears stable until verification demand increases, until an external system integrates directly against certification data and expects real time responses, or until an inconsistency surfaces at the wrong moment under scrutiny. At that point the cost of reconciliation becomes visible all at once. The organization is managing a credibility event rather than an infrastructure upgrade.
Three forces making this urgent now
The pressure to close this gap is no longer theoretical. Three things are converging simultaneously across every professional credentialing sector.
Verification is becoming continuous, not periodic. The expectation across hospitals, enterprises, and regulatory bodies has shifted from periodic confirmation to continuous real time verification. Clinical systems check privilege status before every procedure, not annually. Employer platforms verify credentials at onboarding, during active employment, and on every project assignment. Regulatory portals expect instant responses to licence status queries. Organizations whose data infrastructure runs on batch cycles are being asked to serve real time consumers. The gap between those two speeds is where exposure accumulates.
Credential data is embedded in external systems. Malpractice carriers, hospital credentialing platforms, staffing systems, and regulatory portals are integrating directly against certification data. Inaccuracies no longer stay contained internally. They propagate instantly into systems making real world hiring, coverage, privileging, and compliance decisions. The organization's internal reconciliation timeline is no longer the relevant metric. The relevant metric is the latency between a change in certification status and the moment every downstream system that consumes that status reflects it accurately.
AI is being introduced on unstable foundations. The pressure to deploy AI assisted credentialing is accelerating. Automated privilege checks. Predictive MOC alerts. Anomaly detection. All of these are arriving before most organizations have established the architectural foundation they require. AI does not create data consistency. It amplifies whatever patterns exist in the underlying infrastructure. Introducing AI on a fragmented base does not solve the fragmentation. It makes the consequences of fragmentation faster and harder to trace.
What it looks like when the architecture is right
The organizations that have moved beyond the fragmented trust model share one characteristic.

They stopped building systems around the exam event and started building systems around the credential record as a living data object.
A living credential record is not a static database entry. It is a continuously maintained state. The sum of all events that affect a professional's standing in their field. Exam outcomes. Renewal actions. CE completions. Disciplinary events. Verification queries. Status changes.
When the credential record is designed as a living data object, every downstream question becomes a read against a maintained state. Not a manual assembly from four disconnected systems.
Verification becomes a query, not a workflow. Lapse detection becomes an automatic trigger, not a nightly batch. Eligibility checking becomes a real time call, not a sequential process that runs at 2am.
The staff responsible for certification operations do not shrink. They refocus. On the exception that genuinely requires judgment. On the professional relationship that requires human presence. On the compliance edge case that cannot be resolved by a rule. On the work that actually requires them.
They are not bridges between systems anymore. They are credential professionals.
Three architectural layers make this possible.
A data authority layer. A single unified credential record with unambiguous ownership of every lifecycle event. When systems disagree, the resolution mechanism is codified. Not delegated to whoever answers the phone.
A decision infrastructure layer. Real time status computation driven by explicit, auditable rules. Decision logic is codified, versioned, and tested. A verification query at 11pm gets the same answer as one at 9am. Every decision can be explained and defended.
A trust operations layer. Continuous monitoring of certification states. Automated detection of lifecycle events that require action before they produce downstream inconsistencies. Intelligent routing of exceptions to the right person with the right context already assembled. AI works at this layer, augmenting human oversight rather than replacing governance.
The transition from the first layer through the third is not a single transformation. It is a sequenced investment that starts with the highest exposure gap and progresses from there.
The questions worth asking before anything else
Before investing in a new portal. Before integrating another API. Before introducing AI into any credentialing workflow. Before the next platform migration.
Answer these five questions honestly about your current architecture.
Where is certification authority explicitly defined? Is there a formal documented designation of which system holds authoritative status for each credential state, or does that authority exist by convention and habit that only a few people in the organization fully understand?
Which system is the final source of truth? When systems disagree on a professional's status, what is the governed resolution mechanism? Is it codified in a rule, or does it depend on who is available?
Where are decisions being reconciled manually? What volume of verification responses, lifecycle updates, and exception resolutions require a staff member to manually cross check systems and produce a consistent answer? What does that reconciliation cost in time, and what windows of inconsistency does it create between cycles?
How fast can a certification be verified externally? What is the actual end to end time from an external verification request to a confirmed authoritative response, and how does that compare to what the hospitals, regulators, insurers, and employers who consume your data now expect?
Is AI being layered onto a stable decision architecture? Before introducing AI driven capabilities, has the organization established the data authority and decision infrastructure that AI requires to produce trustworthy outcomes rather than amplified inconsistency at machine speed?
The answers identify where the architecture is creating the most exposure. They are the starting point for the work. Not a platform evaluation, not a vendor selection. A structured mapping of where trust is currently maintained through reconciliation rather than through system design, and a prioritised view of how to close those gaps.
How we approach this
We work with credentialing organizations where decisions carry institutional consequence. Medical boards. Nursing bodies. Bar examining authorities. Financial licensing bodies. Engineering certification organizations. Technology credentialing programs. Exam delivery and verification platforms.
What we have observed across these engagements is consistent. The organizations that are ahead of this shift did not get there by buying a platform. They got there by making an architectural decision about what their organization actually produces.
Not an exam. A trustworthy, consistent, verifiable decision about professional qualification status.
Once that decision is made, the engineering work becomes clear. Which systems need to share data they currently do not share. Which decision logic needs to be codified rather than delegated. Which verification flows need to be rebuilt around a real time query rather than a batch assembled response. Which exceptions need to route through governed workflows rather than whoever picks up the phone.
The first engagement we run is a Trust Architecture Assessment. A structured diagnostic, typically three to four weeks, focused on current credential data flows, decision logic, system architecture, and gap against the maturity model described in this post. The output is not a consulting report. It is a working document. A clear map of where certification data lives, how it flows, and where authority is ambiguous. A prioritised gap inventory with operational cost estimates attached. A sequenced investment roadmap with defined next steps.
We do not begin with a proposal. We begin with a diagnostic. Because the organizations we work with need to understand where they are before they can decide where to go. And we need to understand their specific architecture before we can say anything useful about how to improve it.
If this post describes what you are seeing in your own infrastructure, the assessment is the right first conversation.
Before you modernise another portal, integrate another API, or layer AI onto your credentialing workflows, map where trust currently lives in your architecture. That map is the starting point for everything that follows.
infarsight.com/services/data-engineering
Questions this post is designed to answer
Why are professional credentialing organizations becoming data authorities? Because the downstream systems that depend on certification data now interact with it continuously and programmatically, not periodically and manually. When a hospital credentialing platform checks physician status before every procedure, when an employer ATS verifies credentials at onboarding, when a regulatory portal queries licence status in real time, the certification body has become a data service for an entire profession whether or not it built its infrastructure for that role.
What is the fragmented trust model in professional credentialing? It is the architecture that results from systems being built and acquired incrementally over years without a governing vision for trust as a first class concern. Exam platform, candidate registry, certification status system, MOC tracking, verification API, disciplinary database, and reporting layer each built for their own purpose, none designed to share data in real time. Trust in this model is maintained through manual reconciliation rather than through system design.
Why is real time credential verification difficult for most certification bodies? Because the data required to answer a verification query lives across multiple systems that were built at different times, use different identifiers for the same professional, and exchange data via batch processes rather than real time event feeds. Assembling a current verification response requires querying all of these systems and reconciling the results, which takes the combined time of all systems in the chain.
What is the decision layer in credential data architecture and why does it matter? The decision layer is the governed, explicitly architected system that sits between credential data storage and external engagement. It codifies the rules that determine certification status at any given moment, routes exceptions through defined workflows, and produces consistent auditable responses to verification queries. Without this layer decisions are slow, inconsistent, and difficult to defend. Most credentialing organizations have systems of record and systems of engagement but have not built the decision layer that connects them.
How should credentialing organizations think about AI readiness? AI readiness in credentialing requires a stable decision architecture as a prerequisite. AI assisted verification tools, predictive compliance alerts, and anomaly detection consume and amplify whatever data patterns exist in the underlying infrastructure. On a fragmented architecture, AI produces faster and harder to trace inconsistencies. The correct sequence is to establish data authority, build the decision layer, validate governance, and then introduce AI on a stable foundation. Organizations that reverse this sequence will be managing AI amplified operational failures while trying to retrofit governance. That is significantly harder and more expensive than addressing the architecture first.
What does a credential trust architecture assessment involve? A structured three to four week diagnostic focused on current credential data flows, system architecture, decision logic, and gap against the maturity framework. The output is a map of where certification data lives and where authority is ambiguous, a prioritised gap inventory with operational cost estimates attached, and a sequenced investment roadmap. It is a working document designed to drive decisions, not a consulting report designed to justify further engagement.
What is the right first step for a credentialing organization that wants to improve its data infrastructure? A diagnostic rather than a platform evaluation. Before selecting technology the organization needs a clear map of where credential data lives, which system holds authoritative status for each credential state, where manual reconciliation is filling architectural gaps, and what the specific exposure from each gap looks like in operational terms. That map is the foundation for all subsequent architecture and investment decisions.
How does fragmented credential data create regulatory exposure? When certification status data across systems is not synchronised in real time, there are windows during which the data state the organization believes is authoritative does not match the data state external systems are consuming. If a disciplinary action, a certification lapse, or an eligibility change occurs during one of those windows, downstream systems may act on stale data. In regulatory environments where the credentialing body is the designated authority for professional qualification status, inconsistencies create exposure for the organization, for the professionals whose records are affected, and for the institutions that relied on the incorrect data to make privileging or coverage decisions.
If this post raised questions about your data architecture: Data Engineering for High Stakes Operational Environments
If the verification lag problem resonated: Integration Services for Multi System Credential Platforms
If you are evaluating AI readiness in your credentialing workflows: Intelligent Automation for Regulated Operations